


Harrison.Rad 1.5: Clinical reasoning that makes structured draft reporting possible
By Dr Jarrel Seah, Neuroradiologist and Chief Medical & AI Officer at Harrison.ai
Ask any radiologist what they wish for, and somewhere on that list you’ll hear: “More time.” Time to focus on the complex cases. Time to mentor the next generation. Time to think. Not time spent typing the same phrases for the hundredth chest X-ray that week.
That’s what’s driven everything we’ve built at Harrison.ai. Eight years building and deploying radiology AI in production – as radiologists, alongside radiologists – means we’re not modelling the problem from the outside. That’s what we bring to this.
Today we’re releasing Harrison.Rad 1.5: a radiology foundation model delivering improved clinical reasoning, stronger accuracy on complex findings, and better anatomical precision. AI-assisted draft reporting is one of the research use cases this reasoning capability unlocks.
Harrison.Rad 1.5 is live at chat.harrison.ai.
Before we get into the detail, hear it directly from our team: Dr Aengus Tran on why we built this, Dr Suneeta Mall on what changed under the hood, and a demo you’ll want to see for yourself.

Disclaimer: This radiology foundation model has not been reviewed, approved, or cleared by any regulatory authority for medical or clinical use. The model is not intended to diagnose, treat, or prevent any disease or medical condition, and it must not be used as a substitute for professional clinical judgment.
Experience Harrison.Rad 1.5 today.
Explore what’s possible when foundation models are purpose-built for radiology.
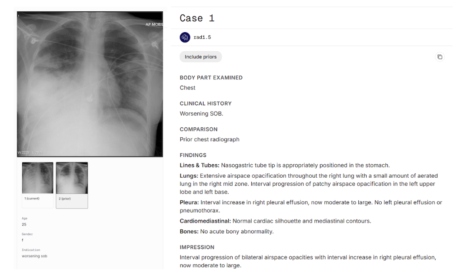
What’s changed
The question I always start with is simple: does the model get better where it counts? With Harrison.Rad 1.5, the answer is yes, and the gains show up most clearly on the cases that matter most.
Harrison.Rad 1.5 is a comprehensive upgrade to the model’s radiological capabilities across the plain-film domain. The improvements span three areas that would matter most in a radiology setting:
Improved clinical reasoning on complex studies.
The model is better at reasoning through studies with multiple findings. These are the cases where cognitive load is highest and the risk of a missed finding is real. It’s more precise in how it distinguishes between similar-looking pathologies and more reliable in how it reasons about what it sees.
Stronger anatomical localisation.
Findings are more accurately placed in anatomical context. When the model identifies something, it’s better at telling you exactly where it is. This matters for report quality and for clinical decision-making.
Better performance in areas of high complexity.
Abdomen, pelvis, and spine imaging represent some of the most demanding reads in plain film. Harrison.Rad 1.5 delivers meaningful gains in these areas, reflecting targeted work on the cases that carry the highest clinical stakes.
These improvements are underpinned by a significantly expanded training dataset: approximately 6 million medical imaging studies, a 33% increase over Harrison.Rad 1. They also include 18 million clinically crafted instruction pairs specifically targeting clinical reasoning, anatomical localisation, measurement, and longitudinal comparison.


Experience Harrison.Rad 1.5
Explore what’s possible when foundation models are purpose-built for radiology
The evidence: Harrison.Rad 1.5
We’ve benchmarked Harrison.Rad 1.5 against the most capable AI models in the world, both domain-specific radiology models and general-purpose frontier models:
- Domain-specific: MedGemma 27B and 4B, MAIRA-2, CheXOne Reasoning, CheXOne Instruct, ChexAgent 8B
- General-purpose: Claude Opus 4.7, Gemini 3, GPT-5.4, Llama 4 Scout
Harrison.Rad 1.5 is the only model evaluated to pass a mock examination in the style of FRCR 2B Short Case (a qualifying exam for radiologists practising in the UK). It achieved a median score of 86.5 against a pass mark of 73.2, independently verified using the Angoff method, and passed more than half of all exam sheets. Harrison.Rad 1 scored 71.0.*
Harrison.Rad 1.5 comes in two variants: Agent, our full reasoning agentic system, and Core, our base radiology foundation model.
* Data on file.
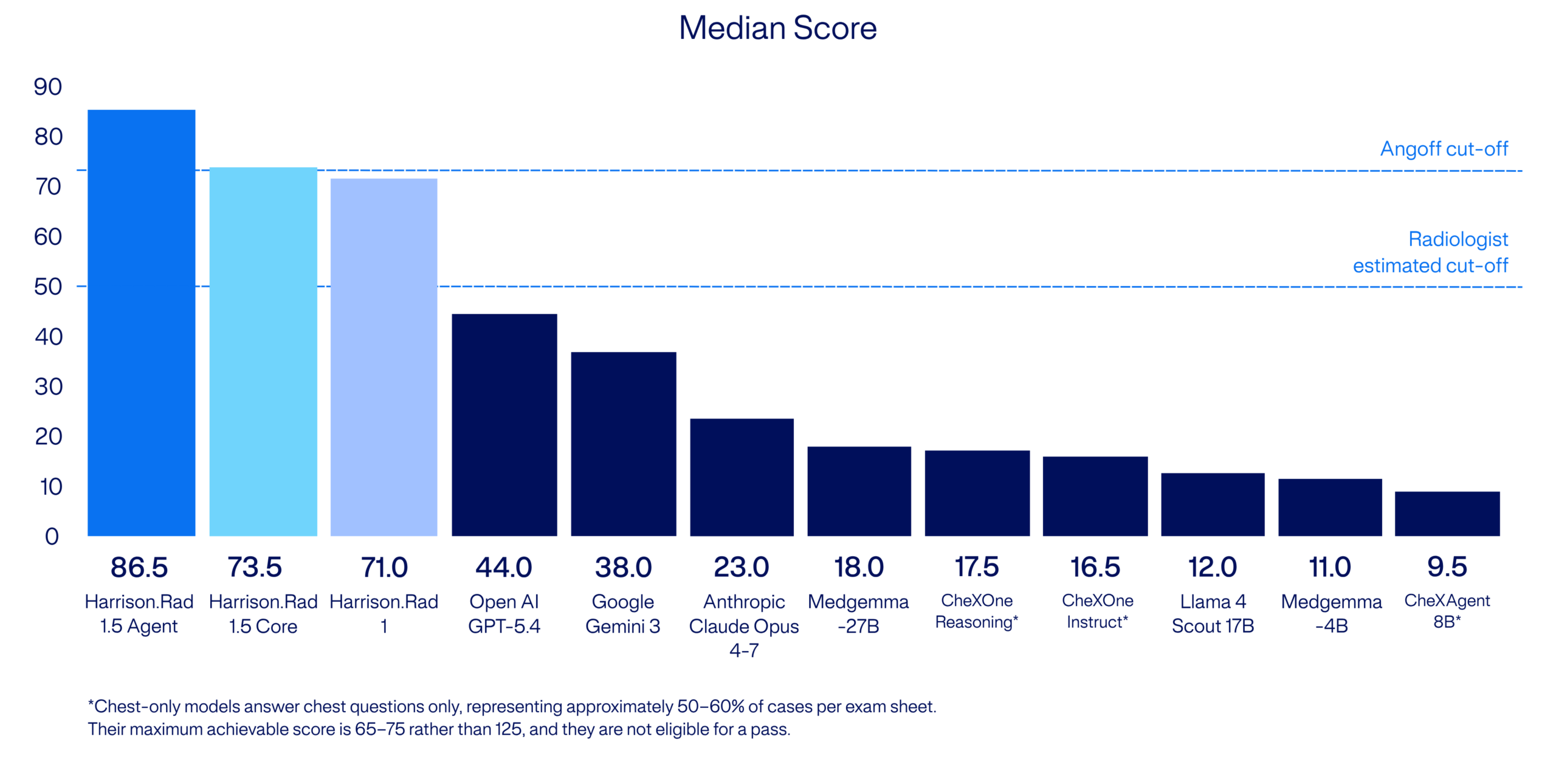 Among domain-specific radiology models: MedGemma 27B scored 18 and MedGemma 4B scored 11. Chest-specific models (MAIRA-2, ChexOne Reasoning, ChexOne Instruct, and ChexAgent 8B) are eligible for chest questions only and scored no higher. Among general-purpose frontier models: GPT-5.4 scored 44, Gemini 3 scored 38, Claude Opus 4.7 scored 23, and Llama 4 Scout scored 12. No other model evaluated passed, whether purpose-built for radiology or among the most capable general-purpose models in the world.
Among domain-specific radiology models: MedGemma 27B scored 18 and MedGemma 4B scored 11. Chest-specific models (MAIRA-2, ChexOne Reasoning, ChexOne Instruct, and ChexAgent 8B) are eligible for chest questions only and scored no higher. Among general-purpose frontier models: GPT-5.4 scored 44, Gemini 3 scored 38, Claude Opus 4.7 scored 23, and Llama 4 Scout scored 12. No other model evaluated passed, whether purpose-built for radiology or among the most capable general-purpose models in the world.
Built on a proven foundation
Harrison.Rad 1.5 doesn’t start from scratch. It builds on its predecessor Harrison.Rad 1 across a clinical exam benchmark, an independent assessment and peer-reviewed research.
- FRCR 2B Rapids radiology mock examination*: Scored 85.67%, every other model scored below 50%.
- Independent assessment by Mass General Brigham and the American College of Radiology, published August 2025.
- Peer-reviewed research, American Journal of Roentgenology (Hong EK et al., 2026)
- Lowest hallucination rate: 5.7% (vs. 10.8–53.8% for competitors)
- Preferred by every reader, chosen as best report in 39–67% of cases
- Highest report acceptability: 61–76% accepted without modification
- Best diagnostic balance – 66.0% sensitivity, 94.6% specificity across 13 abnormalities
*The FRCR 2B Rapids was the preceding format of the UK radiology fellowship exam, retired by the Royal College of Radiologists in 2025 and replaced by the Short Case as the current standard.
Experience you can’t shortcut
These results don’t surprise me, but they didn’t happen by accident either. Harrison.ai has been building toward this for years, long before foundation models became the talking point of the industry. That head start is grounded in something most new entrants don’t have: a clinical AI footprint deployed across 24 countries, operating at scale across real radiology workflows. .
That experience, understanding how clinicians work, where AI succeeds and where it fails in production, is what informs how we build. Rad 1.5 is built independently of our clinical products, but by the same team that has spent years in the hardest parts of radiology AI. That depth of domain knowledge is what you can’t manufacture overnight. When you’ve been doing the hard work in production, at that volume, for that long, the gap to models built in a hurry shows up exactly where it should: on the exam that qualifies human radiologists.
Try it
At Harrison.ai, we ship when we have something that makes a real difference. Harrison.Rad 1.5 does.
Harrison.Rad 1.5 is live at chat.harrison.ai. Upload a study and see for yourself.
Dr. Jarrel Seah is Chief Medical/AI Officer at Harrison.ai. He leads the clinical evaluation and validation programme for Harrison.ai’s radiology foundation models.