
Meet Harrison.Rad 1.5, our next-gen foundation model that can draft reports from images using priors and clinical context.
What Harrison.Rad 1.5 can do.
Demonstrated improvements across the clinical tasks that matter most – benchmarked on simulations of the FRCR 2B Short Case and Rapids, the exams that certify UK radiologists.
Disclaimer: This radiology foundation model has not been reviewed, approved, or cleared by any regulatory authority for medical or clinical use. The model is not intended to diagnose, treat, or prevent any disease or medical condition, and it must not be used as a substitute for professional clinical judgment.
*
Draft report generation
Takes a radiology image, reasons over the clinical context, and produces a structured draft report. Written in radiologist-style narrative prose: something precise to interrogate, not a blank page to fill.
Longitudinal reasoning with priors
Automatically compares the current study against prior imaging and surfaces interval change, described in plain language, not as a flagged checklist. The comparison happens at the moment the case opens.
Precise anatomical localisation
Findings placed with greater anatomical specificity, including quantitative measurements such as cardiothoracic ratio. Meaningfully stronger on the spine, abdomen, and post-procedural imaging, areas of the highest diagnostic complexity.
Complex multi-finding reasoning
Improved performance on high-cognitive-load studies with multiple findings, the cases where a finding is most likely to be missed. Stronger coverage of rare-but-real findings outside the classical reporting ontology.
Style and template adaptation
The model adapts to the clinical question being asked, not one lens applied to every scan. Reports read the way radiologists actually narrate.
Multi body part coverage
Full plain-film coverage across chest, abdomen, MSK, spine, and beyond. Targeted improvements in critical and emergency cases, bone lesions and masses, C-spine, lines and tubes, and abdominal pathology.
Draft reports that read like a radiologist wrote them.
Harrison.Rad 1.5 reasons across the image, prior studies, and clinical context to produce structured draft reports – written the way radiologists actually narrate.
Example clinical scenarios to try:
- Post-lumbar fusion follow-up with prior imaging
- Query fracture on shoulder X-ray
- AP chest with clinical history of SOB
Upload the image or series.
Prior studies and clinical context are optional, but they’re where Rad 1.5 shows what it can really do.
The only AI foundation model evaluated to pass the UK radiologist fellowship exam.
FRCR 2B Short Case – the exam every other model failed.
Harrison.Rad 1.5 was benchmarked against the FRCR 2B Short Case*, the exam used to certify UK radiologists, against leading competing models — both domain-specific and general-purpose frontier models.
Harrison.Rad 1.5 reached a median score of 86.5, clearing the exam’s pass mark of 73.2. No other evaluated model passed.
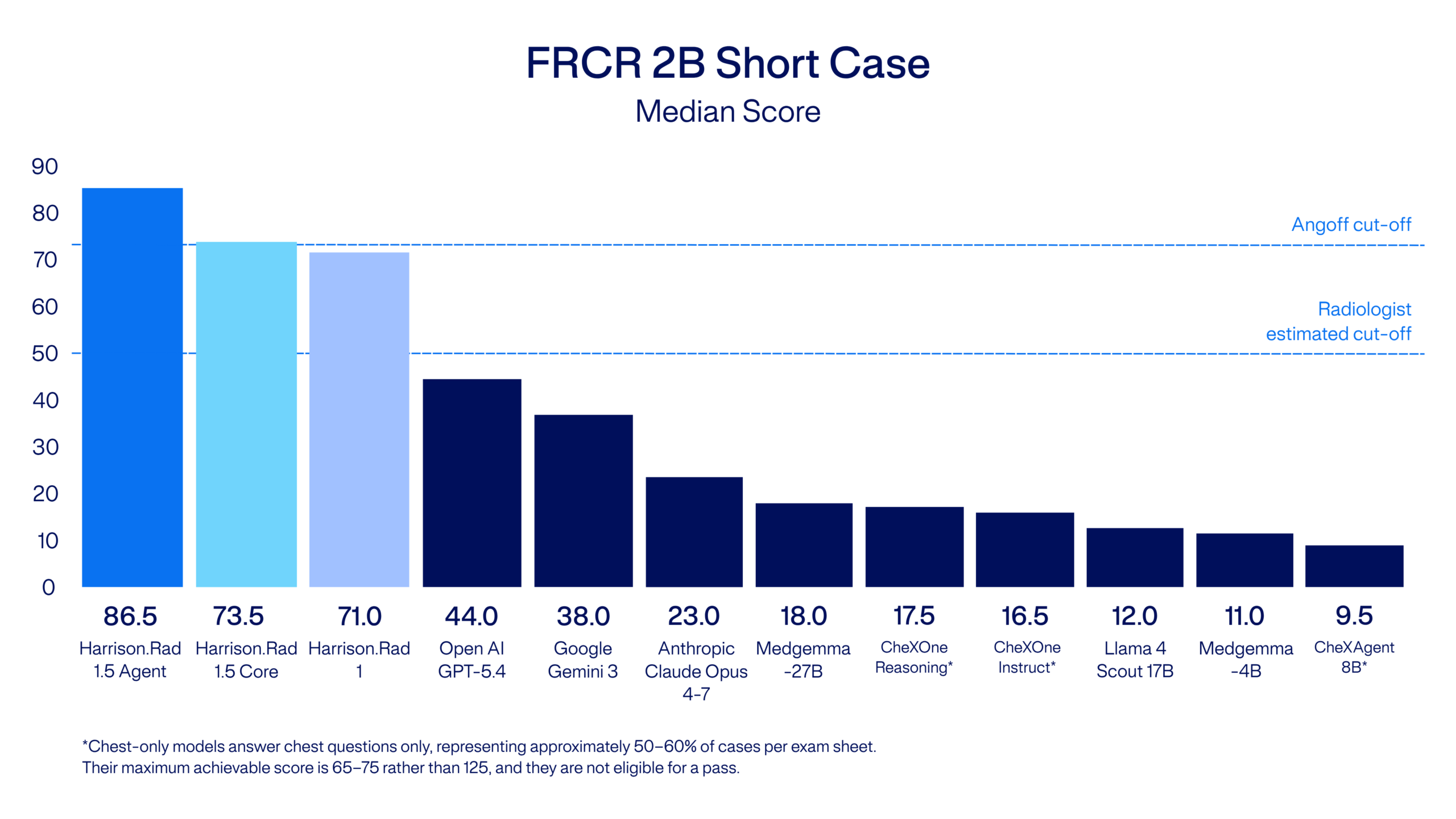 Among the general-purpose frontier models evaluated, OpenAI GPT-5.4 scored 44, Google Gemini 3 scored 38, and Anthropic Claude Opus 4.7 scored 23. Of the domain-specific radiology models: MedGemma-27B scored 18, Llama 4 Scout scored 12, and MedGemma-4B scored 11. No model other than Harrison.Rad 1.5 passed.
Among the general-purpose frontier models evaluated, OpenAI GPT-5.4 scored 44, Google Gemini 3 scored 38, and Anthropic Claude Opus 4.7 scored 23. Of the domain-specific radiology models: MedGemma-27B scored 18, Llama 4 Scout scored 12, and MedGemma-4B scored 11. No model other than Harrison.Rad 1.5 passed.
Rad 1.5 passed more than 50% of exam sheets. All non-Harrison.ai models passed zero sheets.**
Harrison.Rad 1.5 comes in two variants: Agent, our full reasoning agentic system, and Core, our base radiology foundation model. Both cleared the FRCR 2B Short Case pass mark.
* As measured by mock examinations, actual FRCR 2B Short Case questions are not publicly available.
** Data on file.
FRCR 2B Rapids: the previous standard.
The FRCR 2B Short Case replaced the FRCR 2B Rapids format in 2025. We evaluated on both formats to show how the model has improved over time.
On the Rapids exam, Harrison.Rad 1.5 passes 24.3% of full exam sheets* – a 2.4× improvement on Harrison.Rad 1, which passed approximately 10%. Every other all-body-part X-ray model evaluated passed zero.**

Harrison.Rad 1 set the field’s benchmark on the Rapids when it launched in 2024, averaging 51.4 out of 60 against a passing score of 54, and scoring 85.67% overall — while every competitor scored below 50%. Harrison.Rad 1.5 extends that lead further still.**
The direction is consistent across both exam formats: where Harrison.ai’s models improve, the gap to every other evaluated model widens.
* As measured by mock examinations, actual FRCR 2B Rapids questions are not publicly available.
** Data on file.

Harrison.Rad 1.5
A radiology-specific foundation model that can draft structured reports.
The numbers behind Harrison.Rad 1.5
Median FRCR 2B Short Case score (pass mark 73.2)
Improvement on FRCR 2B Rapids vs. Rad.1. All other models 0% pass rate.
Diagnostic studies in training – 33% more than Harrison.Rad 1
Clinically crafted instruction pairs trained end-to-end
The groundwork that makes this possible.
Harrison.Rad 1.5 builds on Harrison.Rad 1, evaluated more rigorously than any other radiology AI model we are aware of, and the subject of independent assessment and peer-reviewed research.
- FRCR 2B Rapids: 85.67%, every other model evaluated scored below 50%.
- Peer-reviewed in the American Journal of Roentgenology (Hong et al., 2026.) involving radiologists at Stanford, Mass General Brigham, and Seoul National University Hospital. Harrison.rad.1 was preferred by every reader, with the lowest hallucination rate of any model evaluated.
- Independently assessed by Mass General Brigham AI Arena and the American College of Radiology in the Healthcare AI Challenge.

Try Harrison.Rad 1.5 now.
Many radiology foundation models are behind closed doors. Harrison.Rad 1.5 is available to try right now.
No waitlist and no demo request.